OpenAI Just Gave Solo Founders a Team
Everyone’s calling it a speed feature. It’s not. It’s an org structure — and I ran it on a live repo to find out.

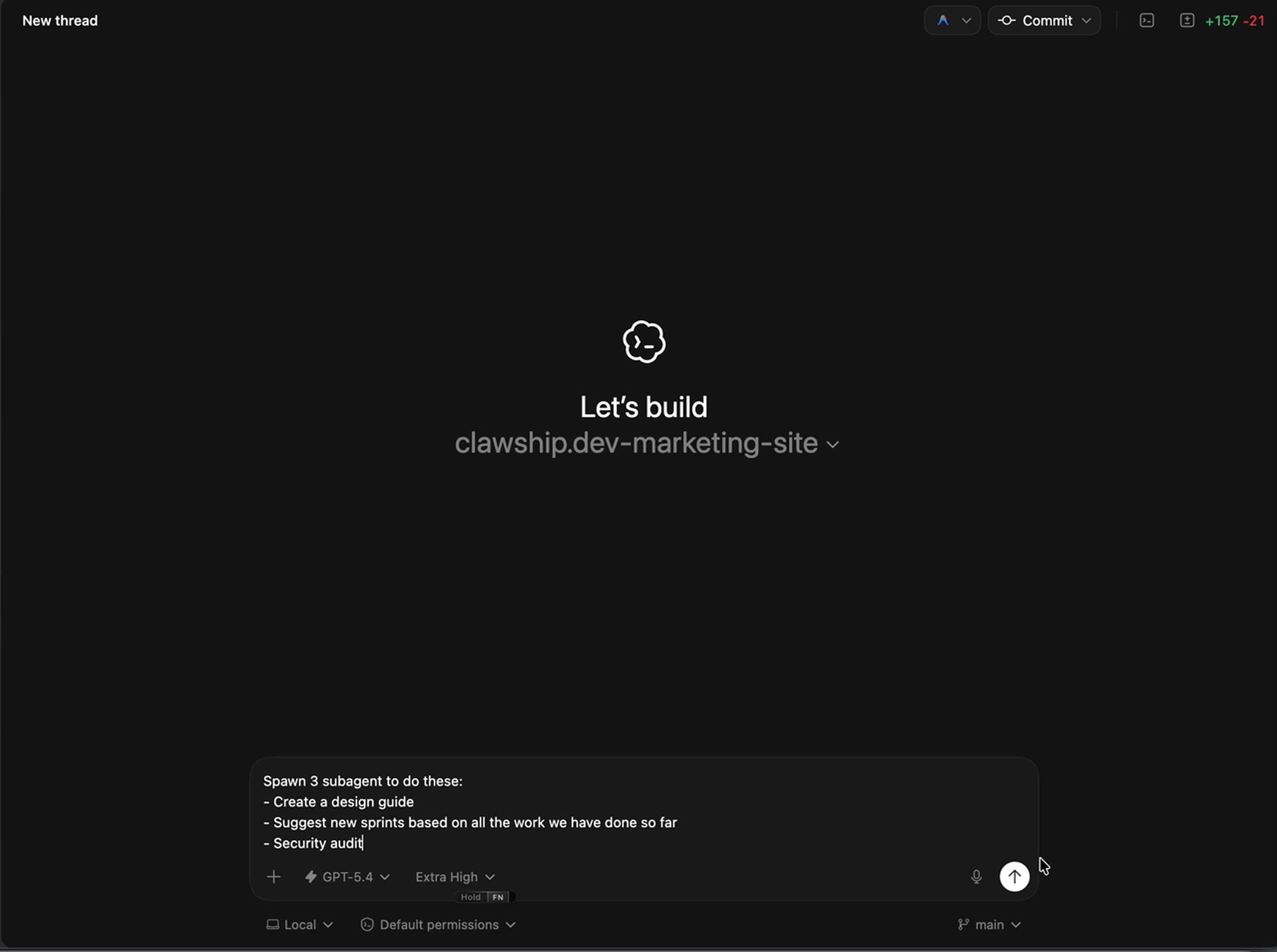
Yesterday, OpenAI shipped subagents for Codex in general availability.
Not a preview. Not behind a feature flag. GA. Available now.
Sam Altman said something when the Codex team announced it worth sitting with: the hardcore builders he knows have all switched to Codex.
Hardcore builders.
That’s not enterprise positioning. That’s for people who build like their life depends on it — solo founders, small teams, people doing the reps.
That’s us.
Here’s what this actually means — what it is, how it works, and what happened when I ran it.
Everyone’s Getting the Headline Wrong
Every article right now is calling this a parallelism feature.
Run multiple agents at once. Go faster. More throughput.
That’s technically accurate and completely misses the point.
The reason subagents matter has nothing to do with speed. It has to do with a problem that every single person using AI coding tools has hit, whether they know what to call it or not.
OpenAI calls it context pollution and context rot.
Here’s what that means in plain English.
When you run a complex task in one thread — exploring a codebase, writing new features, running tests, debugging failures, updating docs — everything accumulates in the same context window. Exploration notes. Stack traces. Dead ends. Outdated observations. The model’s working memory fills up with noise from its own process.
Over time, the signal-to-noise ratio degrades. The model starts making decisions based on stale observations from earlier in the thread. Output quality drops.
This isn’t a model capability problem. It’s an architectural problem.
Subagents fix the architecture.
Each agent gets a clean context. It does its job. It reports back with a focused summary. The main agent — your orchestrator — never sees the mess. It only sees the output.
The main agent stays clean the entire time.
That’s the actual insight. Not parallelism. Role isolation with orchestration.
How It Actually Works
Codex ships with three built-in agents out of the box. No config required.
default — General-purpose fallback. Works for most things.
worker — Execution-focused. For implementation tasks. Designed to run large numbers of small tasks in parallel.
explorer — Read-heavy. For exploration and scanning. Stays out of your write scope.
You can use these immediately just by referencing them in a prompt. But the real power is in custom agents.
Custom Agents
Custom agents live as TOML files in one of two places:
~/.codex/agents/— personal agents available across all your projects.codex/agents/— project-specific agents checked into your repo
Every custom agent needs three things:
toml
name = "reviewer"
description = "PR reviewer focused on correctness, security, and missing tests."
developer_instructions = """
Review code like an owner.
Prioritize correctness, regressions, security, and missing test coverage.
"""Everything else is optional but powerful. You can override the model, reasoning effort, and sandbox mode per agent:
toml
name = "explorer"
description = "Lightweight scanner for codebase mapping and dependency tracing."
developer_instructions = """
Map code paths. Trace dependencies. Surface relevant context.
Do not write or modify files.
"""
model = "gpt-5.3-codex-spark"
model_reasoning_effort = "low"
sandbox_mode = "read-only"Model Selection
Two main choices:
gpt-5.4 — Full reasoning. Use for your main orchestrator and anything requiring judgment. Complex logic, security analysis, synthesis.
gpt-5.3-codex-spark — Optimized for speed. Use for worker agents. Exploration, scanning, mapping, quick summaries.
The pattern that works: main agent on gpt-5.4 with high reasoning effort. Worker agents on Spark with low or medium reasoning effort.
You pay more in tokens. You save more in time and context quality.
Runtime Controls
Two global settings worth knowing:
toml
[agents]
max_threads = 6
max_depth = 1max_threads controls how many agents run concurrently.
max_depth controls delegation depth — whether agents can spawn their own subagents.
Keep max_depth = 1 unless you specifically need nested delegation. Subagents inherit the parent session’s sandbox and approval state. They’re parallel workers inside the same runtime policy, not independent sessions with looser permissions.
Try This Right Now
Open Codex and run this prompt on your project:
Review my project. Spawn 3 subagents:
1. Check for security vulnerabilities
2. Identify missing test coverage
3. Suggest performance improvements
Wait for all three, then give me a prioritized action list.That’s your first run. Ten minutes. See what comes back.
What I Actually Ran
I wasn’t trying to build something new when I tested this.
I had work that had already shipped. I needed the documentation to catch up.
Sprint summary. Feature matrix. Changelog. Regression checklist. Backfilled narrative for the March 16-17 iterations. The kind of work that always falls behind because it competes with building. It’s not the product. It’s the record of the product.
I asked Codex to handle it.

First it inspected the repo — git history, existing docs, everything that had actually been pushed versus everything the docs claimed existed.
Then it spawned three subagents with non-overlapping write scopes:
A sprint agent to create a new sprint summary for the March 12-17 work.
A PM tracking agent to update the feature matrix, changelog, and regression checklist so the docs matched live code.
A session-history agent to backfill the narrative docs with the missing March 16-17 iterations.
Three jobs. Three owners. No shared files. No coordination overhead.
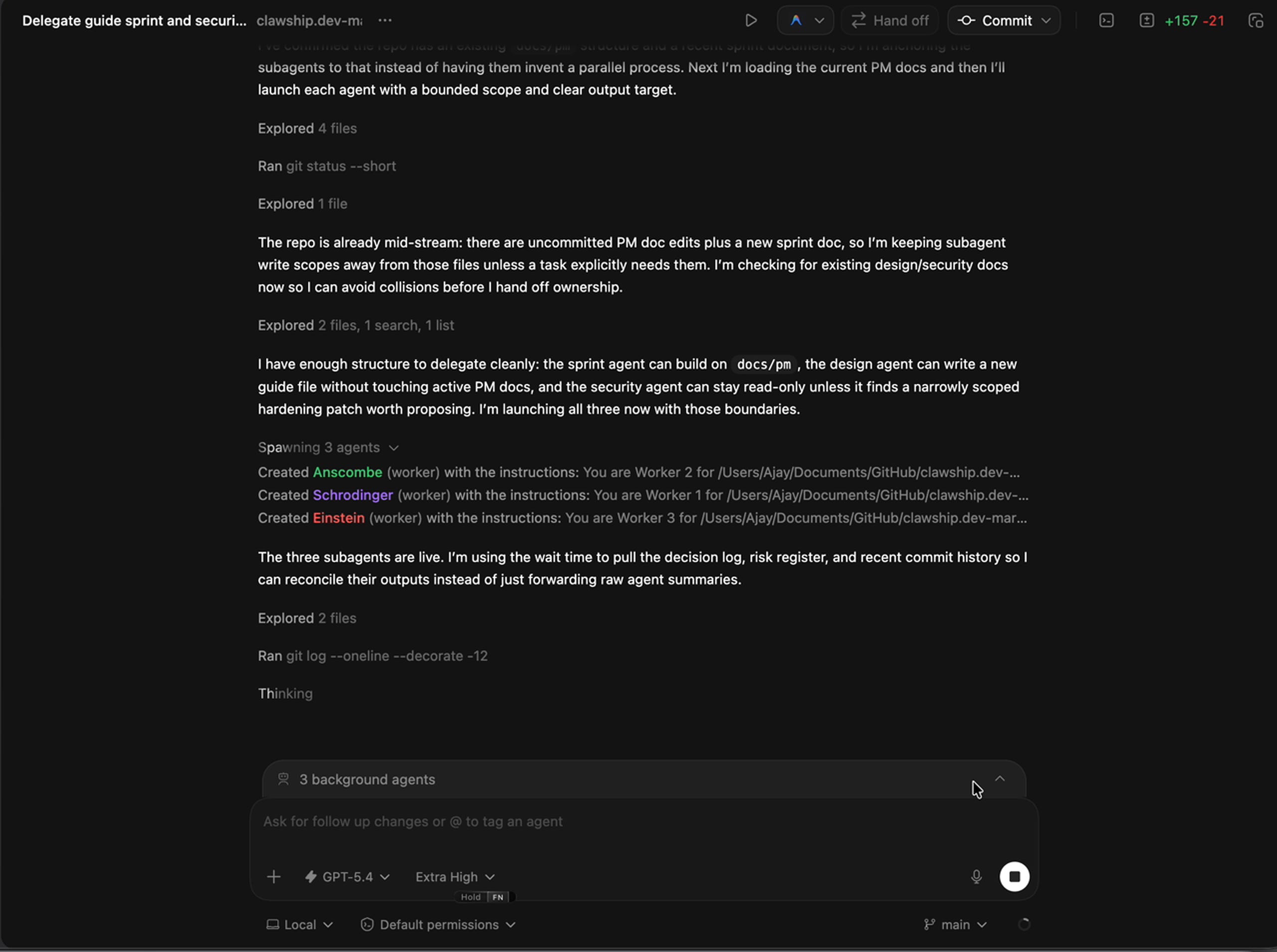
Ten minutes later, all three reported back.
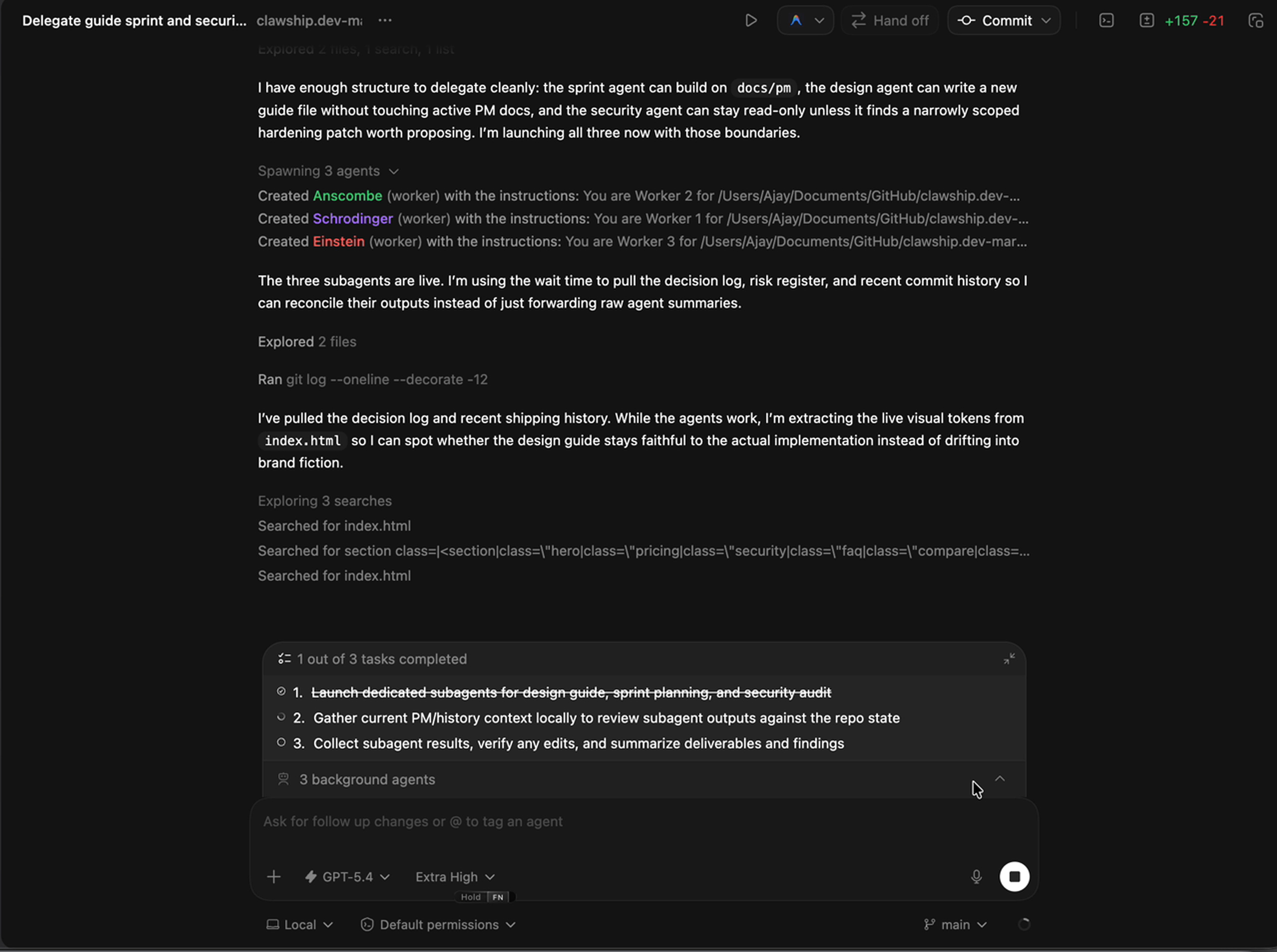
The Moment
The PM tracking agent flagged something on its way out.
It had removed stale $7 pricing language from the docs.
Not because I asked it to catch pricing errors. Because the docs no longer matched the code, and it was doing its job.
That’s when I stopped.
Not because it was impressive. Because of what it meant.
The docs weren’t just incomplete. They were confidently wrong. In multiple places. The kind of wrong that lives quietly in a repo for weeks until someone makes a decision based on outdated information.
That’s not a writing problem. That’s a reconciliation problem.
And reconciliation is exactly what subagents are built for — because the real work isn’t typing new content. It’s reading what exists, comparing it against reality, and surfacing the contradictions.
One agent in one thread would have done that sequentially, accumulating noise the whole way through. Three agents with clean ownership did it in parallel and reported back with focused outputs.
The main agent focuses on decisions. The subagents handle the noise.
What This Replaced
Before subagents, I’d budget 45-90 minutes of focused senior work for the same job.
Read recent commits. Inspect diffs. Update multiple docs. Catch contradictions. Review the final state.
If humans were splitting it: an engineer doing repo archaeology plus a PM doing a docs pass afterward. Two people. Handoff overhead. Still probably missing something.
Ten minutes. Three focused agents. One consistency pass.
That’s not a speed upgrade.
That’s a different way of operating.
When to Use Subagents (and When Not To)
Use subagents when the work has clean separable parts — PR review, codebase exploration, documentation sync, bug triage across multiple issues, test coverage where one agent writes and another validates.
The rule: if you can assign a job title to it, you can probably make it a subagent. Most knowledge work has job titles.
Do not use subagents when:
Agents need to write to the same files — you’ll get conflicts. Tasks are sequential where step two depends on step one — agents can’t coordinate mid-run. The task is simple and single-file — unnecessary overhead and token cost.
Subagents consume significantly more tokens since each one does its own model and tool work independently. Use them when parallelism genuinely makes sense, not as a default.
What This Actually Signals
This isn’t AI helping you go faster.
This is AI helping you operate at a scale that used to require a team.
Think about what a real code review actually requires. Someone tracing code paths. Someone checking security and correctness. Someone verifying the APIs. Someone synthesizing all three into priorities.
That’s four roles. Before yesterday, a solo founder either did all four passes sequentially in one degrading context window, or didn’t do it at all.
Now the structure exists.
And critically — you steer individual agents as work unfolds. This isn’t fire-and-forget automation. You’re in the loop. You can redirect a running subagent, stop it, or close completed threads.
You don’t get to remove yourself. You move up a level.
The senior engineer doesn’t write every line. They decompose the problem, assign roles, synthesize findings, make the call.
That process is now available to someone with a laptop and a Cloudflare Worker.
Not approximately. Actually.
The Part That Doesn’t Change
Subagents fail when the work isn’t actually separable.
The quality of the output is still a function of the quality of the roles you define.
A narrow, opinionated agent with clear instructions outperforms a vague general-purpose one every time. Once one agent has too many responsibilities, you lose most of the benefit — mixed responsibilities create mixed context. The output gets blurry.
You still need judgment. You still need to know when decomposition makes sense and when it doesn’t.
AI removes friction. It doesn’t remove responsibility.
But if you have judgment, and you’ve been doing the reps, the tools just handed you an organizational structure you couldn’t have bought.
Build while the gap is open.
Reply and tell me what task you’d split into subagents first.
— Aj, @thevibefounder